 Kurze Bytes: Webcrawler ist ein Programm, das das Internet (World Wide Web) auf eine vorgegebene, konfigurierbare und automatisierte Weise durchsucht und bestimmte Aktionen für gecrawlte Inhalte ausführt. Suchmaschinen wie Google und Yahoo verwenden Spidering, um aktuelle Daten bereitzustellen.
Kurze Bytes: Webcrawler ist ein Programm, das das Internet (World Wide Web) auf eine vorgegebene, konfigurierbare und automatisierte Weise durchsucht und bestimmte Aktionen für gecrawlte Inhalte ausführt. Suchmaschinen wie Google und Yahoo verwenden Spidering, um aktuelle Daten bereitzustellen.
Webhose.io, ein Unternehmen, das direkten Zugriff auf Live-Daten aus Hunderttausenden von Foren, Nachrichten und Blogs bietet, hat am 12. August 2015 die Artikel veröffentlicht, die einen winzigen, in Python geschriebenen Webcrawler mit mehreren Threads beschreiben. Dieser Python-Webcrawler kann das gesamte Web für Sie crawlen. Ran Geva, der Autor dieses winzigen Python-Webcrawlers, sagt Folgendes:
Ich schrieb als "Dirty", "Iffy", "Bad", "Nicht sehr gut". Ich sage, es erledigt die Arbeit und lädt innerhalb weniger Stunden Tausende von Seiten von mehreren Seiten herunter. Es ist kein Setup erforderlich, keine externen Importe. Führen Sie einfach den folgenden Python-Code mit einer Seed-Site aus und lehnen Sie sich zurück (oder machen Sie etwas anderes, da dies einige Stunden oder Tage dauern kann, je nachdem, wie viele Daten Sie benötigen)..Der Python-basierte Multithread-Crawler ist ziemlich einfach und sehr schnell. Es ist in der Lage, doppelte Links zu erkennen und zu beseitigen und sowohl die Quelle als auch den Link zu speichern, die später zum Auffinden eingehender und ausgehender Links zur Berechnung des Seitenrangs verwendet werden können. Es ist völlig kostenlos und der Code ist unten aufgeführt:
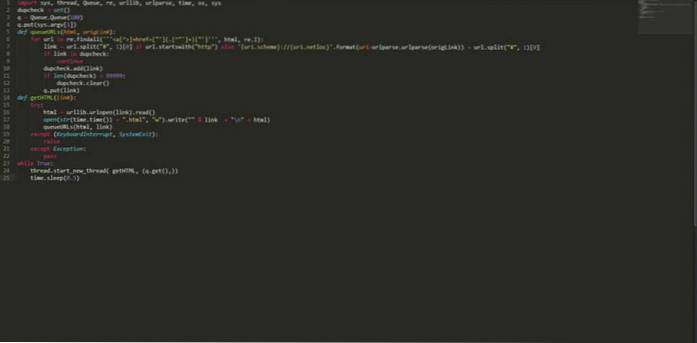
import sys, thread, Queue, re, urllib, urlparse, time, os, sys dupcheck = set () q = Queue.Queue (100) q.put (sys.argv [1]) def queueURLs (html, origLink): für URL in re.findall ("] + href = ["'] (. [^"'] +) ["']", html, re.I): link = url.split ("#", 1) [0] wenn url.startswith ( "http") else 'uri.scheme: // uri.netloc' .format (uri = urlparse.urlparse (origLink)) + url.split ("#", 1) [0] wenn Link im Dupcheck : setze dupcheck.add (link) fort, wenn len (dupcheck)> 99999: dupcheck.clear () q.put (link) def getHTML (link): try: html = urllib.urlopen (link) .read () open (str (time.time ()) + ".html", "w"). write (""% link + "\ n" + html) queueURLs (html, link) außer (KeyboardInterrupt, SystemExit): erhöhen außer Ausnahme: pass while True: thread.start_new_thread (getHTML, (q.get (),)) time.sleep (0.5) Speichern Sie den obigen Code unter einem Namen, beispielsweise "myPythonCrawler.py". Um eine Website zu crawlen, geben Sie einfach Folgendes ein:
$ python myPythonCrawler.py https://fossbytes.com
Lehnen Sie sich zurück und genießen Sie diesen Webcrawler in Python. Es wird die gesamte Site für Sie herunterladen.
Werden Sie mit diesen Kursen ein Profi in Python
Gefällt dir dieser absolut einfache Python-basierte Web-Crawler mit mehreren Threads? Lass es uns in den Kommentaren wissen.
Lesen Sie auch: So erstellen Sie einen bootfähigen USB-Stick ohne Software in Windows 10